WRITE (iocmcf,
& '("MCFGEN Date:", i8, 5x, "Library type:", i3)')
& i_date, nclibtyp
Here, the date is in the format such that 12 January 1995 is
written as 950112. The code for the library type is
WRITE(iocmcf,'("Source Library Id Word:", i12,
& 5x, "Last Changed:", 2x, i6)')
& libid, libdate
Here, libid is meant to be the library identifier packed in
some format, but it is not clear what the components are. The
convention given on page 16 of reference [3] is only followed
for incident photons, because all of the other `mcf.asc'
files have
WRITE(iocmcf,'(i6, 12x, i3, 3x, i3,44x,"*")')
& nnza, negi, numcs
Here, the meaning of the entries is:
WRITE(iocmcf,'(1p, i2,4e11.4,1x,i6)')
& iyi, halflife, elvfd, tmpfd, atm, rpdate
The meaning of the entries is:
WRITE(iocmcf, '(24i3)')
& (C_clean(c_count), c_count=1, numcs)
WRITE(iocmcf, '(i4, i7, 1x, a8)')
& flag, number, string
The type of data is identified by means of the flag. The
dentification is unique in all cases except that
![]() = 12
has two interpretations--its most common usage is as the flag for
energy distributions (
= 12
has two interpretations--its most common usage is as the flag for
energy distributions (
![]() = 4), but it also used for
the angular distribution of gammas. The header line must be used
to distinguish them. A point to be aware of is that for
= 4), but it also used for
the angular distribution of gammas. The header line must be used
to distinguish them. A point to be aware of is that for
![]() = 1 and 2 there is no header line. But these two data
blocks appear only with the first target, and they come
immediately after the list of reactions, before the rest of the
data. We list the types of data blocks ordered in terms of flag because that is what is used by the code mcfbin which
reads the `mcf.asc' file. The user who is accustomed to
working in terms of the data identifier I_number should
consult the following list.
= 1 and 2 there is no header line. But these two data
blocks appear only with the first target, and they come
immediately after the list of reactions, before the rest of the
data. We list the types of data blocks ordered in terms of flag because that is what is used by the code mcfbin which
reads the `mcf.asc' file. The user who is accustomed to
working in terms of the data identifier I_number should
consult the following list.
The content of the data blocks as ordered by flag is as follows.
WRITE(iocmcf, '(1p, 6e11.4)') (ebound(j), j=1, nebi)
WRITE(iocmcf, '(1p, 6e11.4)')
& (temture(j), j=1, numtemp)
WRITE(iocmcf, '(i4, i2, 1x, a16)')
& flag, number, string
For prompt neutrons we have
WRITE(iocmcf, '(1p, 5i5, 5x, 3e12.5)')
& c, I_number, s, igsrt, igend, q0, x1
The meaning of these entries is:
WRITE(iocmcf, '(1p, 6e11.4)')
& (array(j), j=igsrt, igend)
WRITE(iocmcf, '(1p, 6i5, 3e12.5)')
& c, I_number, s, igsrt, igend,
& kin_type, q0, x1, tempture
The differences from the header for
The cross section data follows,
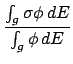
WRITE(iocmcf, '(1p, 6e11.4)')
& (gpsig0(j), j=igsrt, igend)
The cross section data is followed immediately in the file (without an identification flag) by a line containing the number of particles produced by this reaction, including the residual nucleus.
WRITE(iocmcf, '(i2)') parts_produced(1, nrc)
Then come the secondary particles and their multiplicities as
pairs (yo, multiplicity). The residual nucleus is the
last particle, unless it is light enough to be included with
the other secondary particles.
WRITE(iocmcf, '(15i6)') (parts_produced(j, nrc),
& j=2, parts_produced(1, nrc)*2 + 1)
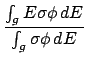
WRITE(iocmcf, '(1p, 6e11.4)')
& (av_en_avail(j), j=igsrt, igend)
WRITE(iocmcf, '(1p, 6e11.4)')
& (qbargp(j), j=igsrt, igend)
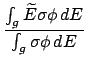
WRITE(iocmcf, '(1p, 6e11.4)')
& (e10barg(io), io = igsrt, igend)
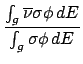
WRITE(iocmcf, '(1p, 6e11.4)')
& (array(j), j=igsrt, igend)
WRITE(iocmcf, '(1p, 4i5, 5x, i5, 3e12.5)')
& c, I_number, s, num_engy_in, neqpb, q0, x1
For this value of the flag the data identifier
I_number is 1. The unusual item in the header is neqpb, the number of equiprobable angular bin edges. (The
number of bins is one less.) The first data entries are the
incident energies in the format,
WRITE(iocmcf, '(1p, 6e11.4)')
& (energy_in(k), k=1, num_engy_in)
The equiprobable angular bin boundaries are concatenated into
a single long array, with a block for each incident energy.
The entries are printed in the format,
WRITE(iocmcf, '(1p, 6e13.6)')
& (cpdi2(k), k=1, neqpb*num_engy_in)
WRITE(iocmcf, '(1p, 6i5, 3e12.5)')
& c, I_number, s, num_engy_in,
& nppbe, neqint, q0, x1
Here, the value of I_number is 3. The number of
equiprobable angular bin edges is
![]() , and the number
of equiprobable energy bin edges is
, and the number
of equiprobable energy bin edges is
![]() . Just as
for
. Just as
for
![]() = 10 (equiprobable energy distributions), the
block starts with the incident energies in the format,
= 10 (equiprobable energy distributions), the
block starts with the incident energies in the format,
WRITE(iocmcf, '(1p, 6e11.4)')
& (energy_in(k), k=1, num_engy_in)
The joint energy-angle distributions are printed in sections. Each section contains, first, an equiprobable angular bin boundary point
WRITE(iocmcf, '(1p, 6e11.4)')
& I1_equi_cos(k, engy_index)
There follows the equiprobable energy bin boundaries for this
cosine,
WRITE(iocmcf, '(1p, 6e13.6)')
& (equi_engy(j), j=1, neqint)
WRITE(iocmcf,'(1p, 4i5, 5x, i5, 3e12.5)')
& c, I_number, s, num_engy_in,
& neqpb, q0, x1
This is standard header information except for neqpb, the number of equiprobable energy bin edges. (The
number of bins is
WRITE(iocmcf, '(1p, 6e11.4)')
& (energy_in(k), k=1 ,num_engy_in)
The equidistributed energy deposition bin boundaries for
the various incident energies are concatenated into a
single array, and this array is printed in the format,
WRITE(iocmcf, '(1p, 6e13.6)')
& (cpdi2(k), k=1, neqpb*num_engy_in)
WRITE(iocmcf, '(1p, 5i5, 5x, 3e12.5)')
& c, I_number, s, 2, 2, q0, x1
In this case x1 is the energy of the ejected gamma.
This line is followed by the energy range
WRITE(iocmcf, '(1p, 6e11.4)') emin, emax
and by the energy of the ejected gamma, four more times!
WRITE(iocmcf, '(1p, 4e13.6)') (x1, i0 = 1, 4)
Note that this is the only situation in which the values
of emin and emax get printed, even though they
are present with all of the data in the `library'
file.
WRITE(iocmcf, '(1p, 4i5, 2e12.5)')
& c, I_number, s, ndata, q0, x1
Here, the value of I_number is 941, and ndata is
the length of the data. The scattering form factors are given
in the format,
WRITE(iocmcf, '(1p, 6e11.4)')
& (scats(j), j=1, ndata)
Incidentally, if
![]() = 1 (grid-based data), there is an
extra phoney-target line containing the interpolation type used for
each value of I_number. The format of this line is,
= 1 (grid-based data), there is an
extra phoney-target line containing the interpolation type used for
each value of I_number. The format of this line is,
WRITE(iocmcf,'("999999" / "MCFGEN Date:", i8,
& 5x, "Library type:", i3,/,
& 3x, i3, " (0) ",
& i3, " (7) ",
& i3, " (9) ",
& i3, " (10) ",
& i3, "(94x) ")'
& ) i_date, 1, (interp_typ(count), count=1, 5)
These entries have the following meanings.